.
What is a three way merge?
Short functions are key to a simple and readable code base. I’m sure you’ve stumbled across several hundred line monstrosities before that are hell to test or reason about.
Here I’ll present a short example on a lesser considered issue surrounding functions, that of three-way merges. The motivation for this is based on a colleague needing to merge in my changes to a file she was already working in. Specifically, the changes were in the middle of a Very Long Function that she was also modifying the body of. The examples here are in C++ and Javascript, but the core point is the same for all programming languages.
I’ll share an example of a horrible merge, then an example of the same code, refactored, in a much easier merge. There’s no special tricks involved — the code is simply pulled apart into smaller, more readable chunks.
Jump straight to the end for some suggestions on how to keep code mergeable.
A three way merge is where one file has been updated by two competing sources simultaneously, and one must merge with the other. You’ll typically only come across this when using source control tools like Perforce or git.
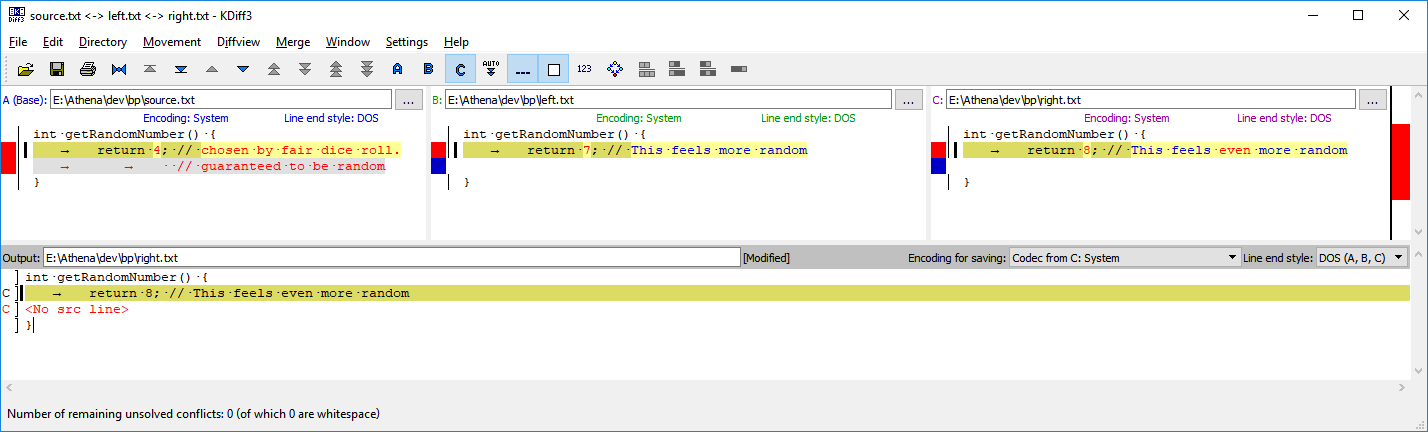
Here’s a simple example of such a merge, presented in the tool KDiff3:
Here we have three files, written by several programmers: Ali (source.txt), Betsy (left.txt), and Carter (right.txt) in KDiff3. Ali is on the left, Betsy in the middle, and Carter on the right. In Ali’s file, you can see a poor implementation of a random number generator, as inspired by XKCD.
Here, source.txt refers to the latest version of a given file that is checked into our source control system, without further changes or additions.
Betsy and Carter have decided this wasn’t random enough, and chose to improve the algorithm, each on their own computer. Betsy thought that 7 was more random, whereas Carter thought 8 was even more random than that.
Betsy decided to check in her change as soon as she wrote it, unaware of Carter’s current herculean efforts to also overhaul the random number generator.
When Carter tries to check in, they realise that the latest version in source control is no longer the source.txt they were working against — rather it’s now the equivalent of left.txt. Unable to automatically sort this out, the source control system offers Carter the ability to perform a manual merge of the three files. This allows Carter to decide what really is the true contents of the file.
At the bottom, we can see the output of the merge. We have decided to choose the Carter’s update as the real, canonical piece of code. We could have also chosen Betsy’s, or simply kept Ali’s original code as is.
Merges are not easy. This was about as trivial an example of a three way merge possible, and yet it’s still possible to make a mistake, or misunderstand intent.
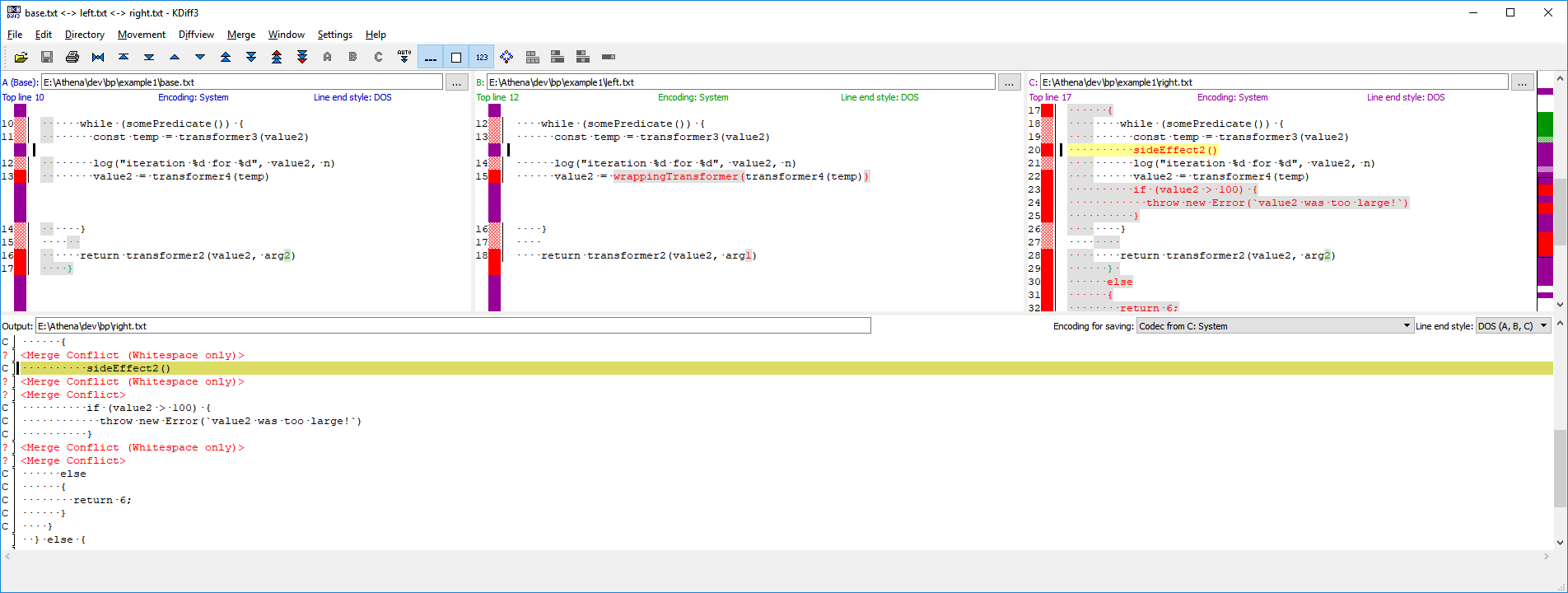
Let’s look at a more complex merge, on a larger function. The provided code is deliberately contrived and obtruse to make a point — the merge and general structure of the code are far easier to comprehend when you reduce complexity. However, this is based on, and representative of, the “worst merge” referred to above. The contents of the code here is not important: the complexity of the shape and the merge is what you should focus on. Don’t waste time trying to follow what the code is really doing.
The first file, long_base.js, is our base file, that two programmers have decided to update and work on.
The second file, long_left.js, drops an else statement on line 7, and tweaks what is happening on line 13 (now line 15).
Our last file, long_right.js, adds extra logging, puts in an extra while loop, changes the default return from 7 to 8, and more. It’s a non-trivial change, and touches multiple areas of the function. In this case, the programmer even decided to use a different brace style, opting for the next line as opposed to current.
Let’s take a look at this in KDiff3. It won’t be pretty.
Even a small subsection of this merge is awkward and uncomfortable to work with. Not only is it difficult to encode the intent of both programmers, it’s actually very easy to merge incorrectly. This could lead to, in the best case, code that doesn’t compile. In the worst case, subtle bugs and ordering effects could creep in.
But it doesn’t have to be this way.
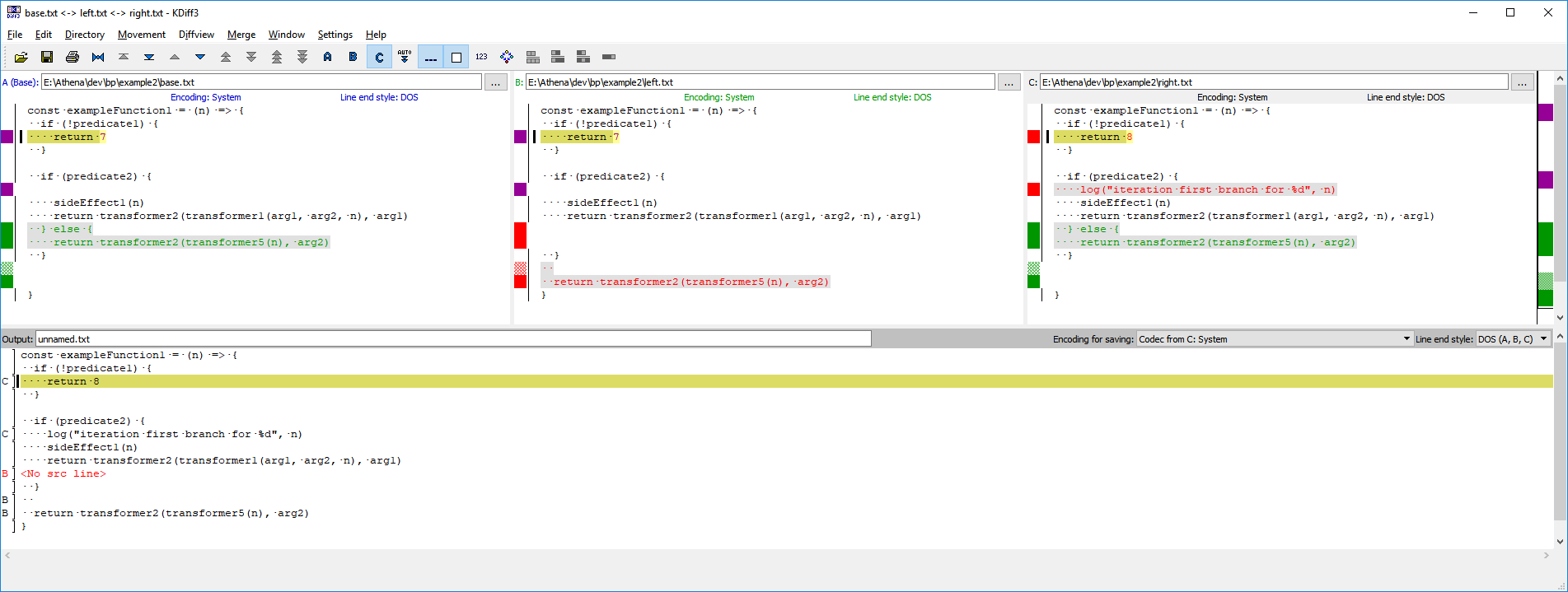
Here are refactored examples of the above code. The following changes have been made:
return 7 into an early return, saving on a layer of indentation throughout most of the function.value1 into the function call, though sometimes it may be more readable to keep it as a well named variable.transformer5. We no longer care about the implementation of it, and changes in indentation level around the function can no longer confuse our merge here. The programmers may have changes to transformer5 in another file which requires its own merge, but here: we don’t know, and we don’t care.Exactly. Unnecessary details have been abstracted away. Even with meaningless variable names and functions, you can now easily follow the entire function with very little mental effort.️
Let’s now look at the merges.
This merge is beautiful. A junior developer, or one with little to no experience in the area, should be able to perform this merge with ease. Even the indentation change has not caused an issue.
As such, we should strive to keep our code as simple and flat as makes reasonable sense. By doing so, we can save much time in bugs and frustration caused by merging in work.
This point on frustration is important — by thinking about how others will interact with our code, we can improve our workflow and working situation not just for ourselves, but for our entire team. Reduce the stress on others, and they’ll be able to do the same for you.
I hope you’ve taken something positive away from this, and let me know if you have any thoughts, agreements or differing views!
🍬