.
Can goto be used responsibly?
Without the goto keyword, modern programming languages would simply not exist. But, given a brief survey of modern developers, you'll quickly find it maligned and shunned. Overuse of goto produces spaghetti code - used carelessly, they will yank a reader's attention back and forth, like someone with too many Wikipedia tabs open. But how did this come to be? Why, if goto is apparently so important to computer science, do people view it with such disdain?
I am not here to talk to you about goto alone. PHP, macros and even poor old bubblesort routinely receive much more negative press than is fair. But these are just examples that help convey a wider idea; that understanding the software of the past can help you write better software today. Writing them off wholesale without a deeper examination is missing a great chance to expand your programming vocabulary.
Let's explore why these examples deserve more credit than is often given to them. There are four major examples covered in this article, so feel free to jump right to whichever section heading scandalizes you the most.
In 1968, the eminent computer scientist Edsger Dijkstra published his now famous paper, “Goto Statement Considered Harmful”, which starts with a bold and clear statement:
For a number of years I have been familiar with the observation that the quality of programmers is a decreasing function of the density of go to statements in the programs they produce.
In simpler terms - “more gotos means more bad code.”
goto shows up in many languages, and all over computer science - but if you're unfamiliar, let's take a quick look at what a goto is.
Let's say you're a local to London city, out for a drive. You know the routes, the shortcuts, the tollbooths to avoid. You're on a three-lane road, and as you drive, you see in the distance a large shimmering portal covering your lane, with a large friendly label above it reading “France”. There are portals for the other lanes, labelled for other countries. As you continue down your lane and drive through the portal, sure enough, you find yourself in the French countryside, or at least what you assume must be France. You have an enjoyable poke around, before yet another portal appears, this time taking you to Tanzania. As you appreciate the tropical scenery, it dawns on you that you have no idea where you are, how you really got here, or how you'll ever get back home. These portals over the road represent what is known as an unconditional goto. Without any further logic, you are simply taken to another part of the program.
It's worth nothing that modern goto, such as in C, C++, PHP, Perl and more, is a far simplified, neutered version of the original. If you've come across goto monstrosities in modern code, you'll realise it pales in comparison to what Dijkstra was dealing with. We'll refer to these two as legacy goto and modern goto.
At the time of Dijkstra's writing, conditional blocks in code, that is, if-then-else statements, did not exist. Instead, languages had unconditional, and conditional goto. FORTRAN, in 1957, had an early form of if statement that would jump the program counter to a different part of the code, based on the value of some variable. While this did the trick, it created a flow of code that was hard to follow around.
What Dijkstra advocated for in his paper, was structured programming, a concept which moved all legacy gotos out of the hands of developers and lowered them carefully into the compiler.
This removes the ability to dangerously place large portals, and instead offers the developer the wonderful if-then-else construct. Developers keep just as much conceptual power as before, but far less opportunity to create code that stump future readers. (Less, not none!)
Here's what a modern if-then-else looks like - it's the bread and butter of imperative programming. This is a classic example of structured programming - you can very clearly see a “backbone” along the left-hand side of the code, creating a clear structure.
void greet(int age) {
if (age >= 18) { // if
std::cout << "Hello there!"; // then
} else {
std::cout << "What's up fellow kids?" // else
}
std::cout << "Bye!";
}
Here's what it would look like without proper structured programming, using modern goto in C++.
void greet(int age) {
if (age >= 18) {
goto greetadult;
} else {
goto greetchild;
}
greetadult: // then
std::cout << "Hello there!";
// Extra goto so we don't
// do a child greet as well
goto end;
greetchild: // else
std::cout << "What's up fellow kids?"
end:
std::cout << "Bye!";
}
The modern goto is readable, as this is in a small function with clear boundaries. But if we look further back, at FORTRAN, we'll see what riled up old Edsger so much.
Here is a typical example of legacy goto in a simple FORTAN function for computing prime numbers. Note the line numbers on the left - a goto could go to any line number in the program.
It's an absolute nightmare to parse - it jumps all over the place. No wonder Dijkstra was fed up with reading code like this!
Let's think about our driving example again for a moment. Each portal represented a single old-school goto. What if these were modern C++ or PHP gotos? What new guard-rails and checks are introduced to stop us landing in the middle of a jungle?
Remember our portal that would teleport us from London, UK, to somewhere in France? That would be denied. A modern goto, rather than letting you go wherever you want, can only move you around an existing function. Our portal then, would teleport us anywhere within London city - but not whisk us away to France, or even further to Tanzania. Rather than being limited only by your entire program, modern goto restricts you to a much smaller scope.
As such, modern goto is no longer free to jump around as it wishes, and the complexity is bounded only by the size of your current function. You can reason about where you'll end up much better. This being said, using goto in a large function is a bit like teleporting you from one end of London to the other. For those unfamiliar with London, which is about 50km wide, going from one end to the other is short enough a journey that technically you'd be able to find your way back, but far away enough that it would still be a large effort.
As such, the problem with modern goto is not the construct itself, but its use within large functions, where more appropriate abstractions such as if, while or switch statements should have been used.
It is like carefully balancing a tower of shopping in your arms, instead of just using a bag. One or two items are fine to hold in hand - a week's worth of dinners is verging on ridiculous!
Where should we use goto then? There are legitimate use cases for this safer version of goto, such as breaking out of nested loops or certain optimized state machine implementations. CPPReference says it is “Used when it is otherwise impossible to transfer control to the desired location using other statements.” - essentially, as a last resort.
But for the most part, outside of these specific use cases, the general advice of “Don't use goto” holds true.
It might sound like I’m flip-flopping here. First I tell you goto is good, then I give you a history of why it’s bad, after which I turn around and give you some examples where it’s useful, ultimately finishing off by suggesting you avoid it where possible. What’s my point?
Software development is complex, with a long and storied history. goto is not a stupid idea dreamt up by brainless engineers who wanted to write bad code. It is simply a stepping stone towards structured programming, which in itself is a stepping stone towards later types such as functional programming, or even newer “no-code” environments. Dijkstra’s seminal paper had a profound influence, summing up existing thoughts and ideas on how to advance software development. This history, as it often does, gets lost to time, and only the core phrase, “goto statement considered harmful” stays on in the collective minds of developers - regardless of what goto or “harmful” mean in the original context.
I encourage you, next time you have a gut reaction to a statement, maybe by seeing a goto in a code review, and are ready to tell another developer “Don’t use X!”, to take a step back. Do you understand why you’re discouraging its usage? Are there times when your suggestion doesn’t hold true? And could this be one of those times?
I am not advocating for goto - I am advocating for intent and deliberate decision making.
Let’s look at a few more commonly condemned ideas, and ask - what is the real issue here?
“Developers hate PHP because it’s a technically inconsistent language with a bad design.”
Quote from Je suis un dev's "Why developers hate PHP".
This is a pretty common view of PHP, and everyone has a story about a terrible PHP website they worked on which caused them all sorts of grief. Yet many later web frameworks were directly inspired by PHP’s incredibly effective “write code and go” approach.
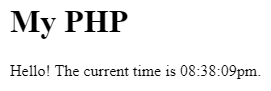
<!DOCTYPE html>
<html>
<body>
<h1>My PHP</h1>
<p>Hello! The current time is <?php echo date("h:i:sa"); ?>.</p>
</body>
</html>
This is a fantastically simple, natural, and lightweight method to compose HTML and server driven data.
PHP let developers move very quickly, and ship websites with little fuss. A PHP developer can write a few lines of MySQL connection code, interleaved with some HTML, save the file as .php, then drag & drop a file via FTP to a web server. All of this is possible without setting up a compiler, or CI/CD pipeline, or convoluted APIs to access databases. No deploy step, no git processes needed: drag and drop, load and run.
Other features that let developers just write code include the $_POST variable (for form submissions), the bundled mysql connection code (for database access) and the $_SESSION variable (for storing information about users, such as login details, across visits). While newer frameworks improve on these, PHP gives you some useful tools and then gets out of your way.
You can (and should) argue that dropping files directly into FTP, or putting database access code into the HTML view, are not ideal ways to build large websites that need a greater level of quality control; but for someone new getting into web development, it’s a very friendly model.
Modern webdev tools have taken this model and evolved the philosophy - React was inspired by PHP, NextJS thanks PHP as inspiration for its “ease of use”, and even more recently Remix harks back to the “good old days of PHP”. I sometimes see snarky comments online about how modern web developers are “reinventing the wheel”, but the truth is that by looking at where previous languages like PHP did well and did not do well, we can improve our future tooling.
The article I pulled my first quote from follows PHP’s development arc, calling it a “victim of its own success” and suggesting that "It’s time to change your vision on this language that has nothing to do with what it used to be.”
I’m not here to say you should or should not use PHP - like any tool, it has appropriate and inappropriate times to use it. Once again however, taking a second, closer look at something commonly seen to be a poor choice can give us a whole new perspective.
In PHP’s case, where the language may have originally been hastily put together with many issues, the developer experience it empowered (particularly with Wordpress) will be an inspiration for all future generations of web development.
Macros are an incredibly useful tool that let us generate source code, from within the source code, at compile time. We can use them to write code that would otherwise not be possible, or abstract away boilerplate, or avoid the overhead of a function call by inlining code directly. But, used too liberally and without enough rigour, macros, in C and C++ at least, can lead to brittle, magical code.
For this section, I will use C to also include C++. We’ll talk about macros, but will not talk about templates, which live in a similar, but different programming niche. We’ll talk about non-C macros (like in Rust or LISP) a little later. We also won’t discuss when to use a macro vs a function here.
Let’s look at a simple MULTIPLY macro in C, which multiplies one given value by another.
#define MULTIPLY(x, y) x * y;
int main()
{
int a = 10
int b = 20;
int result = MULTIPLY(a + 1, a + b);
}
This example is taken directly from “A Guide to Porting C/C++ to Rust”.
You would expect result to be 330; because 10+1 * 10+20 == 11 * 30. However, that’s not how the C preprocessor views it.
Our macro expands to this:
int result = a + 1 * a + b;
C++ follows an order of precedence where multiplication happens before addition. If we add parentheses to show what’s happening, the macro really expands to this:
int result = a + (1 * a) + b;
As such, the result comes out to (10 + (10 * 1)) + 30) == 40! This is certainly not obvious or expected from first glance, but we can confirm this by pasting the original code into CPPInsights.
You could solve this with liberal use of parentheses in the macro, but this is just one of many examples of how macros in C can trip you up (why not try replacing a with a++?). As macros start calling other macros, it’s easy to run into complex behaviour, with terrifying compile errors should you make a mistake.
This is because macros in C, while technically part of the language specifications, are run in the preprocessor step*.* Here, the code is still seen as a malleable blob of text, as opposed to the rich C syntax that later compile steps understand. Because of this, they are known as text substitution macros.
All this leads C and C++ developers to naturally be very wary of macros - they’re powerful tools, but quite easy to create poor and unmaintainable code with. A real problem can occur when these biases are carried over to looking at other languages.
The quickest way to kill a C++ programmer’s enthusiasm for learning the Rust programming language is to exclaim “It has brilliant macro support!”
As we’ve seen, many C++ developers are worried that macros will cause all sorts of awful headaches. But Rust macros are an entirely different beast to those in the C standard. Rust macros are not some extra concept slapped on top and run by a separate process before the compiler; they’re thoughtfully and deliberately built into the language. I would say they’re closer to C++ templates, but even that does them a great disservice, bringing back the terror of template compile errors.
Where C macros will ask you for some untyped “variables” and let you do as you wish, Rust macros require far more rigor.
Let’s write the MULTIPLY macro in Rust. In reality, we’d write multiply as a function, but here we’re using a macro to show off the improvements Rust have made.
macro_rules! multiply {
($x: expr, $y: expr) => {{
$x * $y
}}
}
fn main() {
let result = multiply!(10, 20);
}
Note how strikingly familiar this definition is to a regular function definition. The difference here is, instead of providing actual types like int or u8 to the macro for x and y, we provide what sort of type we’d expect. By using expr, we say “this is an expression which needs evaluating before we put into the code”. Because Rust is smart about this, the issue to do with order of precedence we saw in C simply cannot happen. This smartness is due to Rust implementing what is known as syntactic macros, that is, it understands syntax, and not just text.
Rust also brings a number of other powerful features to macros that make certain classes of code generation possible, that simply wouldn’t be in C. A noteworthy example is the typed_html crate, which lets you convert HTML into rich Rust objects. This is all performed with fully strongly typed code, whereas C macros can leave you feeling around in the dark.
LISP is another example of a language with powerful syntactic macros. In fact, LISP’s macros are arguably the biggest reason for its power and reverence by many programmers. LISP macros, which let you treat your source code as if it were any other data you might want to transform in your program, are uniquely placed to modify and mould your programs to your will.
But, as with Rust, if you have only ever had experience with C macros, then me saying “Check out LISP for its powerful macros!” may sound no better than me saying “You should try this new form of exercise that involves repeatedly smashing your hand with a hammer!”
C, Rust and LISP are of course not the only languages to have macros; macros are as old and widespread as computer science itself. Even modern Javascript can be sprinkled with macros these days, when run through certain compilers such as Babel.
As with the previous sections, if you feel a dull sense of familiarity with the concerns I’ve raised around C macros, ask yourself if you’re dragging those fears along to other languages. If you’ve never picked up Rust or LISP, why not try one of them out? Or, if there are magical macros in your own C codebase, why not spend some time grappling with them to understand what’s really happening? One dedicated programmer willing to document a system can be a great boon to future users of it.
Bubblesort is the runt of the sorting algorithms. It’s pulled out as an example of exactly how not to sort a list, yet due to its simplicity is also often used to teach sorting algorithms from first principles. The premise is simple: Start with the number at one end of a list and compare it to the one next to it. If the first number is larger than the second, swap their positions. Keep doing this until there’s no number next in line smaller than your current one, then go back to the start.
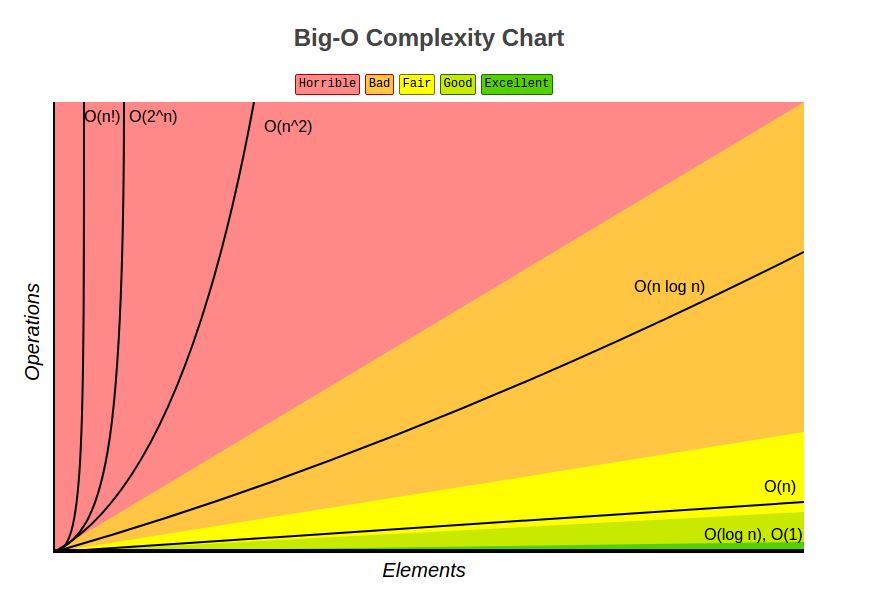
It’s quite elegant, but it’s precisely this elegance that leads it to have a terrible algorithmic complexity (often expressed using Big O notation). Bubblesort has a complexity of O(n²).
Put simply: Every extra element in your list makes the sort take even longer than the element added before it did.
Say sorting 10 elements took 100ms: at 10ms an element, you might imagine that sorting 11 would take 110ms - but actually, it would take closer to 121ms, an increase of 21ms. Adding another won’t increase to 142ms, but 144ms, an increase of 23ms. The amount of time we’re increasing by gets larger with every element. By the time you’re at 100 elements, each extra item adds another 200ms! Not long after this, every extra item is adding entire seconds of waiting time, which quickly balloons to minutes, and then hours, just to sort a list. This unexpected sudden increase in waiting time is exactly why computer scientists spend so much effort on understanding algorithmic complexity in sorts.
This chart is pretty damning for any algorithm with O(n^2) performance, when we know there are sorting algorithms with O(log n) time, suggesting we should just throw the bubblesort out with the bathwater.
However. Bubblesort is actually pretty fast when used on small lists - the sluggishness only presents itself as we sort lists of any real size. But when we’re sorting small lists, say less than 10 elements, it turns out that CPU concerns, specifically cache coherency, play a much larger effect than theoretical complexity. Cache coherency says that if you can write your code to only touch data that’s already in your CPU cache (think of a much smaller, much faster version of RAM), you can save substantial amounts of time that would otherwise be spent reading the data from RAM in the first place.
This property could well be why earlier versions of the Unreal Engine 4’s sort algorithm used a hybrid of different sort algorithms, falling back to bubblesort when the list contains eight items or fewer. Why incur the cost of allocating extra memory, when you can do the last part of a sort extremely quickly with the memory you already have?
Timsort, which is Python’s default sorting algorithm, uses a similar hybrid approach, although it employs insertion sort at small sizes in place of bubblesort. This paper suggests that bubblesort makes great use of the cache at low sizes (though insertion sort beats it out), and this great breakdown really dives into what issues bubblesort really has.
Algorithmic complexity aside however, bubblesort has another fascinating use-case in video games: rendering thousands of visual particle effects to a screen per frame. As bubblesort is just two nested for loops, it can be run one part of a loop at a time against the whole list. This characteristic can be used to partially sort particles by their depth before rendering to screen.
By running one sweep of the sort at a time, rather than waiting for the full list to be completely sorted, the game engine can approach a sorted list over several frames, while being “sorted enough” in the meantime. When combined with z-testing, this provides great speed-ups.
This is a little more difficult if the particles are transparent, however, and whether it provides and acceptable experience for the players is contingent on the art direction of the game. As particle effects are often small or transparent, it’s sometimes not a problem if they’re drawn in the wrong order for a few hundred milliseconds - most of the time, the player simply won’t notice! The art team however, might.
NVIDIA, a company that creates leading graphics cards, have also found that in certain particle rendering scenarios, dividing particles into lists of 31 elements and applying bubblesort is a highly efficient way to achieve local sorting during ray tracing.
Bubblesort is not an algorithm you should reach for in most scenarios, but knowing that there are legitimate cases where it is considered the best option hopefully gives you a new-found appreciation for the algorithm often renamed to “terrible sort”, “teaching sort”, or in one case “crap sort”!
I’ve said it at least four times during this article already, but I’ll finish off by battering you around the head with the point for a fifth and final time: the more you understand the history and reasoning behind certain decisions, the better equipped you are to make your own decisions later. goto, macros, PHP, bubblesort - even if today there are better choices, these all have great uses, both historically, and in the modern day.
Go out and find something, in software or outside in the real world, which turns your stomach. Find a stupid decision you’ve seen somewhere, or a terrible process, and ask: Why is it like this? What events led to this outcome? What should I know before removing this fence?